Pointers on Data Desk Version 6
This is a brief summary of some basics of Data Desk - See the fine book
Learning Data Analysis with DATA DESK
by Paul Velleman for much more complete descriptions.
Data Desk is an easy to use statistics program for PC's and
Macintoshes whose user
interface very much follows the ``desktop'' paradigm present on Mac and
Windows machines. In fact when you open Data Desk, it puts its own version
of the desktop on top of the Mac's usual one.
Each Variable appears
as an icon which you can doubleclick on to inspect the numbers. The different
rows visible when you open such an icon correspond to the different
cases, (individuals) in the relation. You can think of a
relation as being a table with one column for each variable, and
one row for each case. The entry in the corresponding spot of the relation
is the value of the variable for that individual. Different variables
in the same relation will generally be in the same folder.
Operation on data in Data Desk is largely through menus and selection.
Typically to use a menu entry, you need to first select appropriate
variables that the command is to work on. (For example the variables
being plotted ...) Because some operations involve processes that are
not symmetric in their arguments (e.g. you might want one specific
variable on the horizontal axis), there are notions both of selecting a
variable as ``X'' and as ``Y''. Until you select the right arguments,
menu entries will frequently be grayed out. Details
are described below in the section on selection.
Topics covered below include:
- X Variables
- may be selected by holding shift down while clicking on the icon.
- Y Variables
- may be selected by holding control down on PC's
or option down on Macs while clicking on the icon.
- Multiple Selection
- may be accomplished by dragging a rectangle around the icons of interest.
Computation is generally selected from the Calc menu.
Each computation
typically gives a new icon (which can be doubleclicked to open)
in the results folder.
- The Summaries
- submenu of Calc can be used to generate Reports
after the desired summary statistics are chosen. Reports are where you
will find means, standard deviations, ranges, quantiles, and many other
statistics of interest.
- Select Summary Statistics
- from Calculation Options under the Calc menu
offers many choices about what to report for each selected variable.
- Derived Variables
- can also be used for many calculational purposes. More details
below.
- Regression
- is available under the Calc menu and
Regression Options is on the Calculation Options
submenu.
- Confidence Intervals
- are available by choosing Estimate... from the Calc menu.
- Significance (Hypothesis) Testing
- is available by choosing Test... from the Calc menu.
Generating plots generally involves selecting suitable icons (often as x's or y's) and then choosing a suitable plot command.
Plots may be moved by dragging with the mouse.
- Bar Charts
- count the number of cases in a a (usually) non-numeric variable.
- Boxplots
- are produced by the same method as dotplots but add
information such as the 25th and 75th percentiles, outliers, and
the median.
- Dotplots
- involve selecting numeric data as y and categorical data as x.
- Histograms
- display numeric data in bars. Bar width can be adjusted by
choosing Plot Scale from the hyperview menu (sidewise
triangle) to the left of the title of the histogram window.
to the number of cases
- Lineplots
- require the selection of one numeric variable and plot this
against the case number (which starts at 1.)
- Normal Prob Plots
- plots the actual sorted values of the selected variable
against a hypothetical normal distribution determined by the NScores function.
- Piecharts
- like barcharts count up the number of cases.
- Rotating Plots
- require the selection of 3 numeric variables. They may
be set into continued motion by releasing the mouse while dragging.
- Scatterplots
- reuire the selection of numeric x and y variables. The
hyperview menu includes the possibility of adding a least squares
line of regression.
Data is entered into a new or existing variable.
- Creation
- of a new variable is by means of choosing
Blank Variable from the submenu New of the menu Data.
- Cursors
- can be either horizontal or vertical. A vertical
cursor is for editing one entry in a variable. A horizontal
cursor is for inserting a new case.
- Selection of Cases
- for copying or cutting a range of cases is accomplished by dragging horizontally or vertically.
- Pressing shift on PC's while Clicking the Mouse
- allows one to add an additional case to those already
selected.
- Return
- advances to the next case (depending on preferences.)
With a horizontal cursor, it does not automatically create an
empty new case below. Just start typing if you want to create that
new case.
- Tab
- advances to the next variable in the case if the
sequence box (at the top of the right scroll bar for the variable)
is active.
This is possible using commands from the Manip Menu.
If you are just
starting Data Desk and wish to start out by generating random or patterned
data, an easy way to do this is to select enter data from keyboard,
and then cancel from the dialog naming the new variable.
- Generate Patterned Data
- This command can be used to generate a sequence of case numbers (e.g.
1,2, ..., n), or other linearly spaced data.
- Generate Random Numbers
- Possibilities include distributions (uniform, normal, and
Poisson), Bernoulli trials (sequences of 0's and 1's), and binomial
experiments representing cumulative results of Bernoulli trials.
In the dialog box here, the number of cases
will be the number of rows (values) in each variable. By changing
the number of variables requested from its typical default
of 1, you can simultaneously do several simulations.
Layouts are one of the best ways to assemble results for printing. Images of other windows
are moved into layouts by copying and pasting. Alternatively one can
drag icons. Images can then be dragged around and resized within the layout
to achieve the desired effect.
- Creation
- of layouts is by means of choosing Layout from the submenu New of the
menu Data.
- Text
- is entered into a layout by typing it into a scratchpad and then either
- selecting the text and using copy and paste or,
- by dragging its icon into the layout.
- Font size for the text can be selected from the hyperview menu (triangle to the left of the title)
of the scratchpad.
-
- Layouts
- can be used to collect graphics, explanations, and computation
results on one piece of paper.
- Alt Print Screen
- on a PC can place a copy of the DataDesk Desktop
on the clipboard from which it can be pasted into MIcrosoft Paint
and printed.
- Text
- for layouts is best entered in a scratchpad, selected, copied,
and then pasted into the layout.
- Calculation
- can be performed in a scratchpad by entering any
expression legal in a derived variable, selecting it, and then
choosing
Evaluate Derived Variable from the Manip menu.
(So arithmetic expressions not involving variables are allowed here.)
These commands can be used if you want to first enter your data in a text file,
or if you'd like to use a spreadsheet for part of your analysis.
- Export
- from the file menu produces by default a new ASCII tab
delimited file. Before choosing export, select the
variables you wish to export in the order you wish them to appear
in the new file.
- Import
- creates a new relation from such a tab-delimited file.
Variables may be dragged from one relation to another as long as
both relations have the same number of cases.
- Display and Hiding
- can be accomplished by choosing Palettes from the Manip
menu.
- The Paintbrush and Lasso tools
- can be used to
conveniently select cases from a plot. By holding the shift key
down, the cases you click on are added to previous selections rather than
replacing them.
- The Question Mark tool
- can be used on a plot to find out the
variable value which goes with the data point. For this to work, the variable
window with the data you want to see when you click should be open,
and the last variable selected.
-
Sorting and Ranking commands are found under the Manip menu.
- Ranking
- produces a new variable for each selected variable. The
new variable records the position of each case in sorted order
of the variable.
- Sort on Y, Carry X's
- creates a new relation in which the cases have been reordered
by values of the variable chosen as y. All x variables
selected are also copied and reordered in the new relation. A new
variable holding the original case index of each new row also appears.
- Sorting and Ranking Options
- appear below Manipulation Options in the Manip menu.
- Bigger Font Sizes
- may be selected from the hyperview menu - a triangle just to the left of the window title.
These are either created from the Transform menu of
Calc or from New of the Data menu.
Although menu based choices of selected icons may be used,
derived variables
are recorded textually. Doubleclicking on a derived variable
created by a menu command will illustrate how the language of
derived variables works.
- Arithmetic
- expressions like '(5*X[i] - 3*Y[i])/Mean(X)' are allowed.
- If ... Then ... Else ...
- is possible and illustrated in the string example below.
- Sample Derived Variable
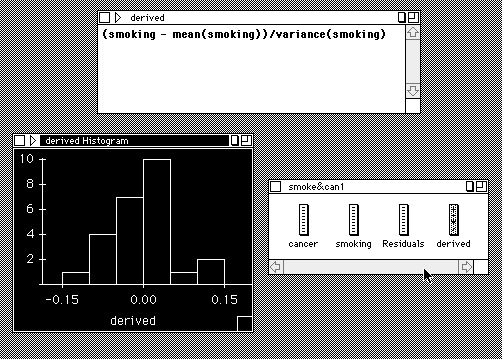
- String
- data can be generated using double quotiation marks, e.g.
if assets > 10000 then
"Big"
else if assets > 2000 then
"Medium"
else
"Small"
- A string Variable_Name
- (possibly within backquotes) may be used in a derived
variable to refer to another. The value of this expression for
each case will be the value of that case in the variable named
by Variable_Name.
- 'Variable_Name[i]'
- refers to the i'th case of the variable named by
Variable_Name.
- Working on a Portion of Your Data
- may be accomplished by the following procedure:
- First select the cases you want to use. The lasso from the
Tools menu under Modify is a convenient way to do this
graphically.
- Choose Assign Selector from the Selection submenu of
the Modify menu. This creates a new variable whose value on the
cases you selected earlier is 1 and 0 otherwise. A corresponding
button is also created.
- When you turn this button on (black color), many subsequent
operations in DataDesk will only use the cases where this variable
takes the value 1; i.e. the cases you selected.
- Grouping data based on the value of a categorical variable
- may be accomplished by the following procedure:
- Select the categorical variable as x.
- Select the other variables you wish to break up as y's.
- Now choose Split into Variables by Groups from the
Manip menu. This will create subfolders, one subfolder
for each value of the categorical variable. Within each subfolder
will be the carried along y values for the cases whose categorical variable
takes the value corresponding to that subfolder.
- Sliders
- are created from the New submenu of the Data
menu.
- have their ranges adjusted by the Plot Scale entry
of the hyperview menu.
- are used as a derived variable would be by referring to the
name of the slider.
- Normal
- ZDistr(y), CumZDistr(y), InvCumZDistr(y).
- t
- CumTDistr(y), InvCumTDistr(y).
- Chi Square
- CumChiDistr(y), InvCumChiDistr(y).
- Binomial
- BinomDistr(y,n,p), CumBinomDistr(y,n,p), InvCumBinomDistr(y,n,p).
- Poisson
- PoisDistr(y,lambda), CumPoisDistr(y,lambda)
- F
- CumFDistr(y,df1,df2), InvCumFDistr(y,df1,df2).
Last Update: